|
| Всё подряд |
О жизни |
Фотозаметки |
Техническое |
|
| Регистрация | Забыл пароль? |
| Парсим сайт при помощи ChatGPT и Python |
| Категория: О жизни | (27 июля 2023) |
|
Итак, сегодня нашёл один интересный сайт. Имя называть не буду, но скажу что на нём очень много mod/xm/nsf файлов, которые очень хотелось сохранить. Но вот проблема. Скачать через софт типа Offline Exporer его невозможно, так как он написан на JS и общение с ним осуществляется через JSON в формате {"path":"/directory MIDI","size":851106123,"type":"directory","numChildren":3}Если внутри есть файл, то ответ будет вида: {"path":"/VGM Rips/1943_Kai_(TurboGrafx-16)/01 Air Battle A (Round Запросы идут site.ru/music/Famicompo/mini0/Cover/04_airou.nsf или Т.е. перед "/VGM Rips/1943_Kai_(TurboGrafx-16)/01 Air Battle A (Round 1).vgz", который в JSON - нужно добавить /music/, чтоб файл скачался. Вопрос сложный. Я не имел опыта парсинга через JSON. Обратимся к ChatGPT. 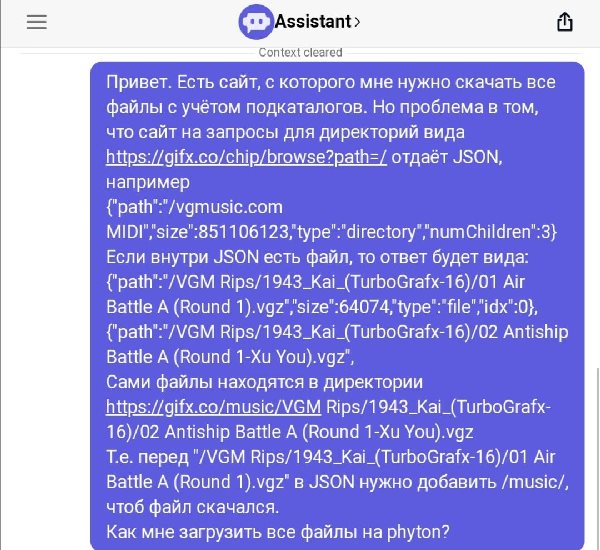 Код он нам выдал. 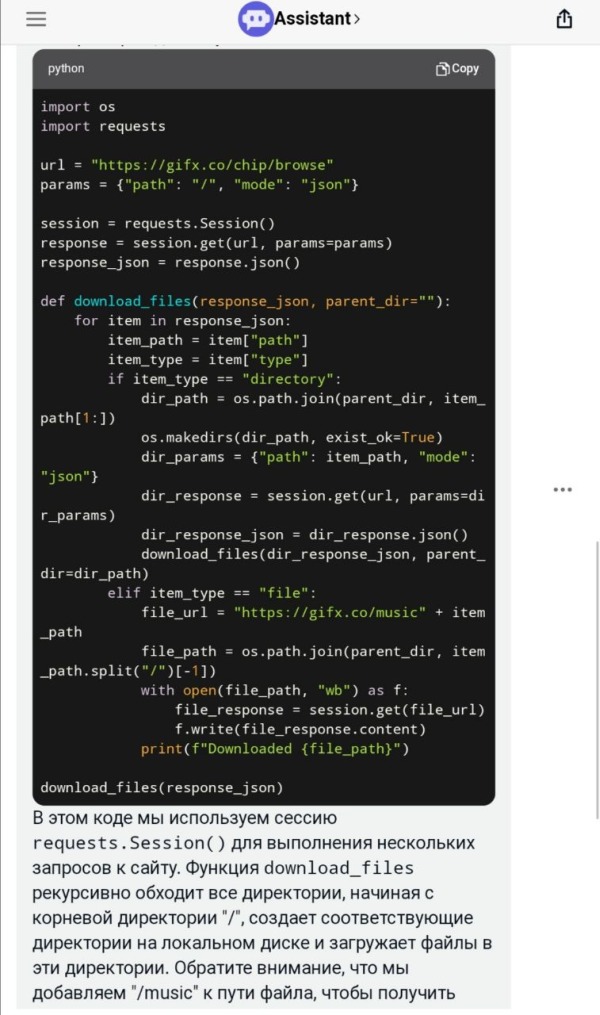 Но, запустив его, я свалился в ошибку, что имена файлов слишком длинные для винды. Снова просим ChatGPT переписать его, чтоб он сокращал имена файлов: 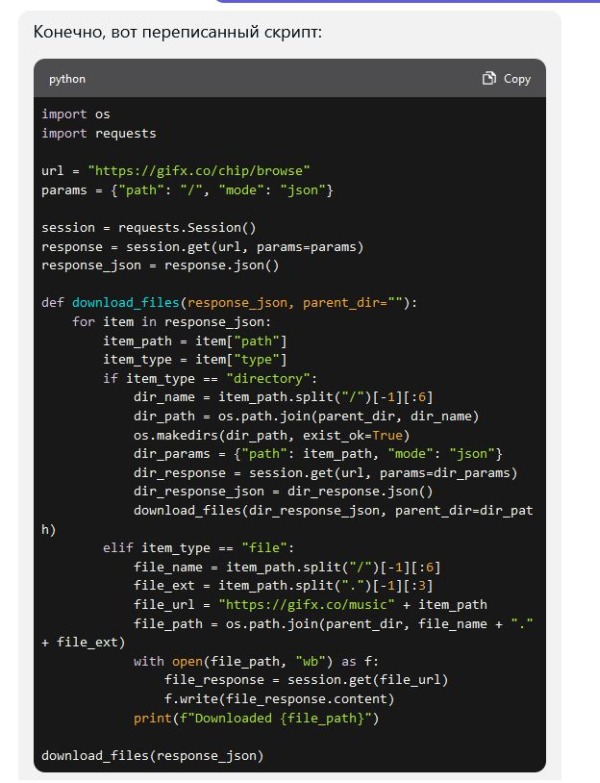 Сокращает, но вот файлы заменяются друг друг другом + возникают ошибки с именами файлов, где находятся пробелы. снова просим подсказать решение: 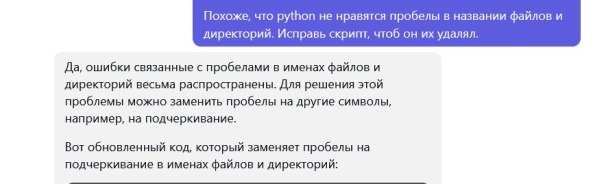 И вот у нас полностью рабочий код. 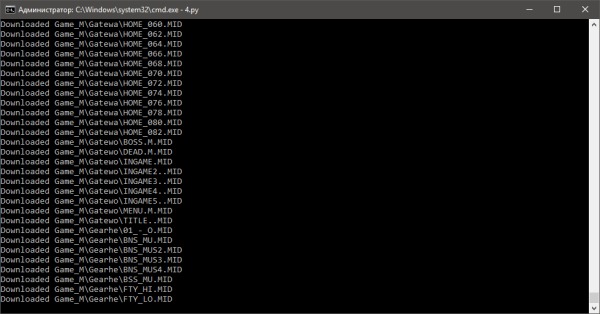 Таким образом, буквально за полчаса мы распарсили сайт, полностью написанный на JS. Мы конечно теряем имена файлов и папок, но учитывая то, что имена папок там по 40-80 символов, и я не знаю Python - это меньшая из жертв. Кому надо, юзаем! import os |
| Просмотров: 339 | распечатать |
| Анон, представься пожалуйста. Регистрация занимает от силы 3 секунды. |
| Разные хренюшки | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Основано Lionovsky в 2009-2010 году |