27 июля 2023 от lionovsky
Но вот проблема. Скачать через софт типа Offline Exporer его невозможно, так как он написан на JS и общение с ним осуществляется через JSON в формате
{"path":"/directory MIDI","size":851106123,"type":"directory","numChildren":3}Если внутри есть файл, то ответ будет вида:
{"path":"/VGM Rips/1943_Kai_(TurboGrafx-16)/01 Air Battle A (Round
1).vgz","size":64074,"type":"file","idx":0},{"path":"/VGM Rips/1943_Kai_(TurboGrafx-16)/02 Antiship Battle A
(Round 1-Xu You).vgz",Запросы идут
site.ru/music/Famicompo/mini0/Cover/04_airou.nsf или
site.ru/music/VGM Rips/1943_Kai_(TurboGrafx-16)/02 Antiship
Battle A (Round 1-Xu You).vgz
Т.е. перед "/VGM Rips/1943_Kai_(TurboGrafx-16)/01 Air Battle A (Round 1).vgz", который в JSON - нужно добавить /music/, чтоб файл скачался.
Вопрос сложный. Я не имел опыта парсинга через JSON.
Обратимся к ChatGPT.
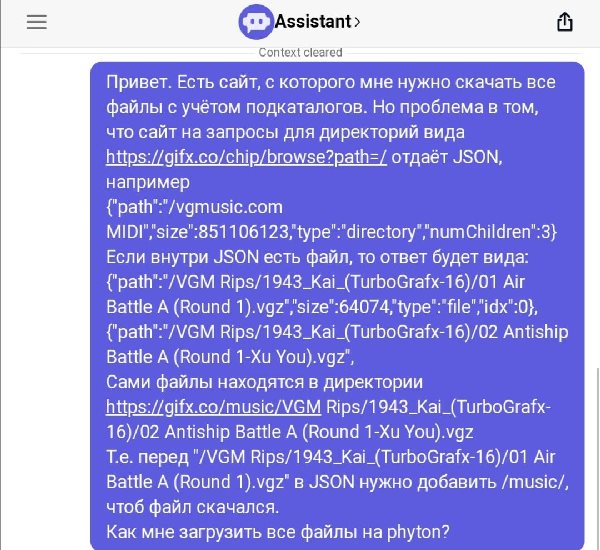
Код он нам выдал.
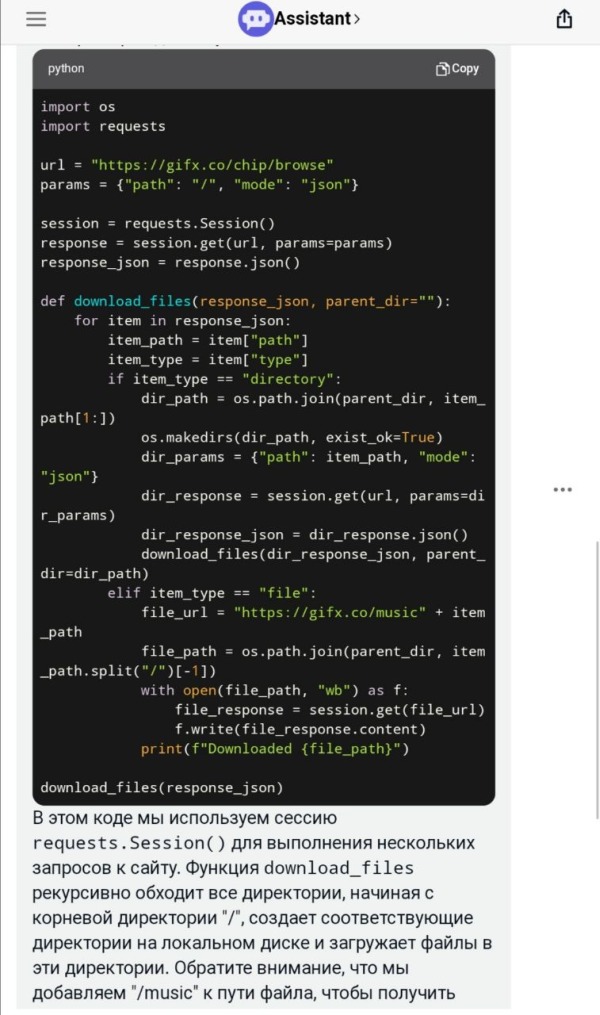
Но, запустив его, я свалился в ошибку, что имена файлов слишком длинные для винды. Снова просим ChatGPT переписать его, чтоб он сокращал имена файлов:
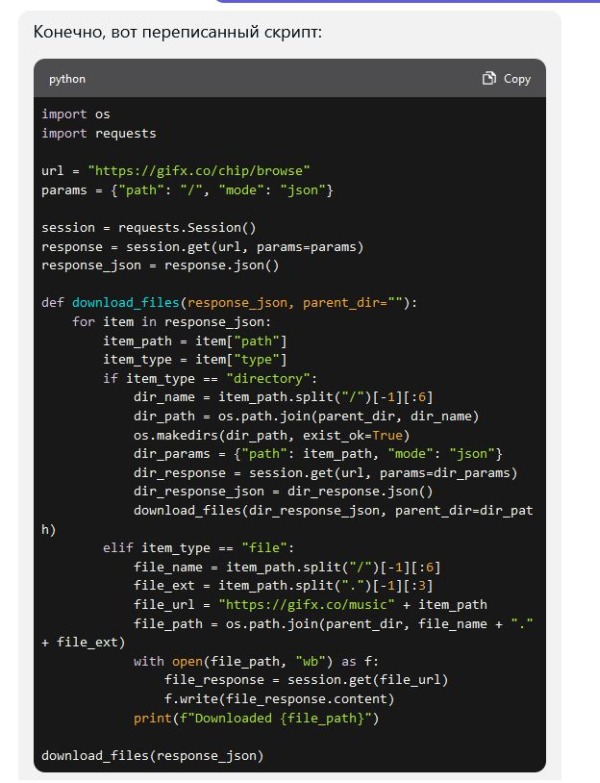
Сокращает, но вот файлы заменяются друг друг другом + возникают ошибки с именами файлов, где находятся пробелы. снова просим подсказать решение:
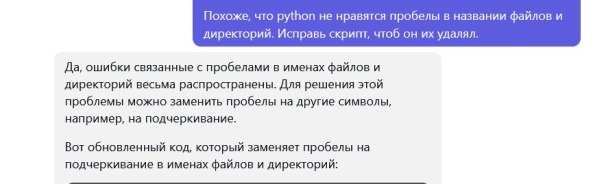
И вот у нас полностью рабочий код.
Таким образом, буквально за полчаса мы распарсили сайт, полностью написанный на JS. Мы конечно теряем имена файлов и папок, но учитывая то, что имена папок там по 40-80 символов, и я не знаю Python - это меньшая из жертв.
Кому надо, юзаем!
import os
import requests
url = "https://site.ru/chip/browse"
params = {"path": "/", "mode": "json"}
session = requests.Session()
response = session.get(url, params=params)
response_json = response.json()
def download_files(response_json, parent_dir=""):
for item in response_json:
item_path = item["path"]
item_type = item["type"]
if item_type == "directory":
dir_name = item_path.split("/")[-1][:6].replace(" ", "_")
dir_path = os.path.join(parent_dir, dir_name)
os.makedirs(dir_path, exist_ok=True)
dir_params = {"path": item_path, "mode": "json"}
dir_response = session.get(url, params=dir_params)
dir_response_json = dir_response.json()
download_files(dir_response_json, parent_dir=dir_path)
elif item_type == "file":
file_name = item_path.split("/")[-1][:6].replace(" ", "_")
file_ext = item_path.split(".")[-1][:3]
file_url = "https://site.ru/music" + item_path
file_path = os.path.join(parent_dir, file_name + "." + file_ext)
i = 2
while os.path.exists(file_path):
# If file already exists, add a number to the file name to make it unique
file_name = item_path.split("/")[-1][:6+i].replace(" ", "_")
file_path = os.path.join(parent_dir, file_name + "." + file_ext)
i += 1
with open(file_path, "wb") as f:
file_response = session.get(file_url)
f.write(file_response.content)
print(f"Downloaded {file_path}")
download_files(response_json)